Pyramid uses heuristics for a range of purposes in the data modeling process, in order to build the data model in the most efficient way. Heuristics are used to create relationships between the model's tables, to define measures, to categorize various columns, and to organize data into logical folders. The heuristic processes reduce the amount of time and effort required by the model-builder and help ensure data model is built in a logical and navigable way.
Heuristics for Joins
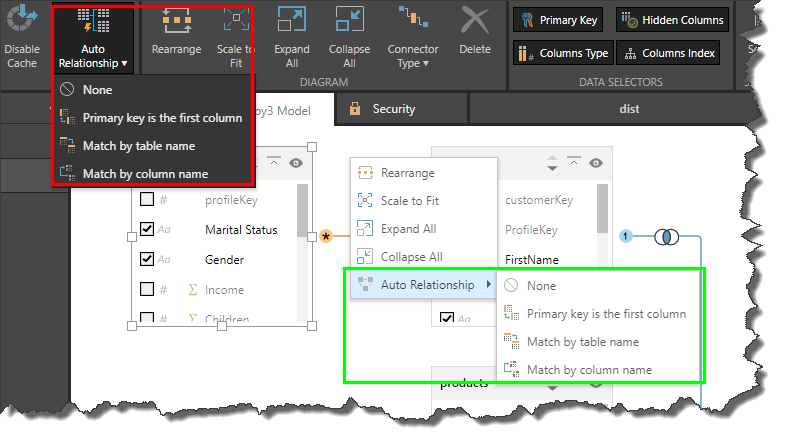
By default, Pyramid uses an algorithm that assumes the first column in each table is the primary key column. It then finds each table's primary key column, and looks for tables containing the same column as a foreign key. Matching primary keys to corresponding foreign keys between tables is a common way of defining joins. However, Pyramid also allows you to change the default algorithm used for defining joins. To do this, right click on the canvas and go to the Auto-Relationship submenu:
- None: do not use any auto-relationship algorithm, and instead define the relationships manually.
- Use Primary Key as the First Column: by default, this algorithm is used to define relationships between the tables. It takes each table's primary key column and looks for tables that contain the same column as a foreign key.
- Match by Table Name: defines relationships by matching tables my name.
- Match by Column Name: defines relationships by matching columns by name.
Related information
The table relationships (joins) that are created based on these heuristics can be edited and managed on the Join context menus and in the Properties panel.
- Click here for more information about Joins